
데이터 팀
데이터 조직은 직접적인 매출 기여가 아닌 부가 가치를 창출
1) 의사 결정에 데이터를 활용( Decision Science )
데이터의 역할: 과거 기록을 기반으로 최적화 및 혁신을 위한 데이터 기반 의사 결정을 필요로 함.
KPI 정의 및 시각화:
- 회사의 KPI를 데이터 기반으로 정의.
- 대시보드를 통해 의사결정권자가 쉽게 판단할 수 있도록 지원.
2) 고품질 데이터 기반 서비스 개선 (Product Science)
목표: 사용자 서비스 경험 개선 및 프로세스 최적화를 통해 비용 절감.
ex) Customer Support팀의 채팅을 챗봇으로 대체하던가 Agent들이 정보를 더 잘 찾을 수 있도록 QA interface를 제공 등
->앞의 Decision Science가 tracking하던 KPI를 개선하는 형태로..

데이터 인프라
데이터 인프라는 데이터 웨어하우스와 ETL(추출, 변환, 적재) 작업을 포함하며, 데이터 엔지니어가 이를 구축한다.
1) 데이터 웨어하우스:
- 대규모 데이터를 구조화하고 저장하기 위한 저장소.
- 대표적 솔루션: Amazon Redshift, Snowflake 등.
2) ETL 프레임워크:
- Airflow: 데이터 파이프라인을 쉽게 정의하고 관리할 수 있는 도구로, AWS, Azure, Google Cloud 등의 클라우드 환경에서도 지원됨.
- SaaS형 ETL 서비스: 코딩 없이 데이터를 이동하며 간편하게 ETL 파이프라인을 구축할 수 있는 구독형 서비스도 제공.
ETL 프로세스는 데이터 웨어하우스 외부의 데이터를 추출하여 정제한 후, 데이터 웨어하우스의 테이블 형태로 로딩하는 작업이다.
ETL 수가 증가하면 실행 순서를 정의하고, 오류나면 수정하는 등 운영상 오버헤드들이 발생한다.
또한 Spark나 Airflow 등의 서버(큰 리소스)를 한번에 할당하면 서버는 항상 가동 중이지 않아, 자원 낭비와 비용 부담이 큼.
-> 쿠버네티스와 같은 컨테이너 기술을 활용하여 필요 시 자원을 동적으로 할당하고, 서버 효율성을 높임. (Docker, Kubernetes 사용)
3) ETL과 ELT
데이터 파이프라인에서 ETL과 ELT의 차이를 설명하면서, 데이터 레이크와 데이터 웨어하우스의 역할을 비교해보자
데이터 웨어하우스는 고비용의 데이터베이스이다. 스토리지나 컴퓨팅을 할 때 돈을 많이 내야한다.
또한 로그 파일과 같은 비정형 데이터에는 적합하지 않으며, 주로 분석된 데이터나 의사결정에 필요한 정보가 저장된다.
그래서 DataLake가 나왔다.
데이터베이스 같은 프로세싱 엔진이라기 보다는 Storage에 가깝다. AWS S3와 같은 클라우드 스토리지가 주로 활용
로그 파일과 같은 대규모 비정형 데이터를 처리하기에 적합하며, 데이터 레이크가 데이터 웨어하우스 앞단에 위치하여 대량의 데이터 저장을 지원
즉 데이터의 크기가 커짐에 따라 데이터 웨어하우스 앞단에 데이터 레이크가 필요해지고
이 때 파이썬 판다스로는 처리하기 어려운 대량의 데이터를 위해 Spark와 같은 빅데이터 처리 플랫폼 사용.

정리하면
ETL은 주로 외부 데이터 시스템의 데이터를 내부로 가져오는 과정
목적지는 데이터 레이크나 데이터 웨어하우스가 될 수 있으며, 데이터가 이미 잘 정제되어 있다면 데이터 레이크를 거치지 않고 바로 데이터 웨어하우스로 이동할 수도 있다.
반면 ELT는 데이터 시스템 내부의 데이터를 조인하거나 처리하여 새롭게 정제된 데이터를 생성하는 과정
주로 데이터 레이크의 데이터를 정제한 후 데이터 웨어하우스에 다시 저장하는 방식으로 이루어진다.
ETL은 주로 Airflow로 구현하며, ELT 역시 Airflow로 스케줄링을 관리
다만 ELT의 경우 데이터들을 조인해 새로운 데이터를 만들 때 DBT라는 툴이 많이 사용
데이터 레이크와 데이터 웨어하우스에 분산된 수많은 테이블을 이해하기 쉽게 정리하는 추상화된 레이어를 올린것
예를 들어, 매출 데이터를 여러 소스에서 가져오는 회사의 경우, 각기 다른 테이블에 흩어져 있는 매출 정보를 조합해 분석가들이 쉽게 볼 수 있도록 DBT가 데이터를 정리하고 구조화
ETL 작업은 스케줄링하여 자동화하고, 문제가 발생하면 이를 해결하며, 오류가 난 파이프라인을 재실행하는 운영 관리가 필요하다.
특히, 특정 ETL 작업이 실패했을 때 그 작업을 다시 실행하는 과정을 백필(Backfill)이라고 한다.
참고로 Airflow는 크게 3가지 컴포턴트로 구성됨: 스케줄러, 웹서버, 워커
그외..
데이터 웨어하우스 기반으로 데이터 분석가는 의사결정자들이 쉽게 판단할 수 있도록 중요한 지표를 정의하고 이를 시각화하는 대시보드를 만든다. 시각화 대시보드에는 대표적으로 세일즈포스의 태블로와 아파치 수퍼셋
이러한 대시보드는 일반적으로 특정 팀이나 개인에게 중요한 지표를 시간의 흐름에 따라 보여주며, 목표 방향에 맞게 가고 있는지를 확인할 수 있도록 해준다. 일반적으로 KPI(Key Performance Indicators)에는 매출액, 월간/주간 활성 사용자 수 등이 포함된다.
또한 데이터 엔지니어는 수집된 다양한 데이터를 조합하여 새로운 데이터를 생성하는 데이터 모델링을 수행하며, 이때 주로 ELT 방식을 사용 ELT 과정에서 많이 사용되는 도구는 DBT
데이터 과학이 고도화되면, 수집된 데이터에서 패턴을 분석해 서비스를 개인화하거나 운영 과정을 최적화하여 비용 절감 및 사용자 경험 개선이 가능해진다. 이러한 개선 효과는 A/B 테스트를 통해 객관적으로 확인할 수 있다. 긍정적인 사용자 경험은 더 많은 사용자를 유도하고, 이는 다시 더 많은 데이터를 생성해 선순환 사이클을 만든다.
머신러닝과 MLOPs
머신러닝이란
프로그래밍을 명시적으로 하지 않고 데이터로부터 패턴을 찾아서 학습을 하는 알고리즘이 머신러닝이다.
굳이 case by case로 코딩안해도 된다는 장점이 있다. 그러나 내부 과정을 설명하기 어려운 블랙박스 특성이 있고, 데이터의 품질이 매우 중요하다. 모델의 예측이 어떤 근거로 이루어졌는지를 설명할 수 있는 능력도 중요한데, 예를 들어, 의사의 약 처방과 같이 판단의 근거를 제공해야 하는 경우가 있다.
MLOPs
데이터 과학자의 머신러닝 모델을 개발부터 배포, 운영까지 효율적으로 관리하는 프로세스. DevOps가 코드 배포와 모니터링을 수행하는 방식과 유사하게, 머신러닝 모델을 위한 배포와 모니터링을 통해 운영 환경에서 모델이 잘 동작하도록 지원. 모델을 테스트하고, 빌드 후 프로덕션에 배포하며, 서비스 상태를 모니터링해 문제 발생 시 롤백 또는 이슈 해결을 관리하는 것이 핵심이다.
MLOps는 모델이 기대대로 잘 작동하는지, 성능 저하 없이 유지되는지 지속적으로 관리하여 안정적인 머신러닝 서비스 제공을 목표로 한다.
빅데이터 처리 프레임웤
대규모 데이터를 효율적으로 저장하고 처리하기 위해 분산 파일 시스템과 분산 컴퓨팅 시스템으로 구성
분산 파일 시스템 (Hadoop Distributed File System)
분산 파일 시스템은 데이터를 여러 서버에 분산하여 저장하고, 복제본을 통해 고가용성을 확보하여 시스템 일부가 고장나더라도 데이터를 안전하게 보관할 수 있다.
분산 컴퓨팅 시스템 (Distributed Computing Framework)
분산 파일 시스템에 저장된 데이터를 읽고 처리하는 기술 초기의 MapReduce와 Hive는 1세대 분산 컴퓨팅 프레임워크로, 데이터를 분산하여 병렬로 처리하는 기능을 제공했습니다. 이후에는 성능을 개선한 2세대 분산 컴퓨팅 프레임워크 Spark가 등장했으며, Spark는 자체 분산 파일 시스템이 없어 HDFS나 S3 같은 클라우드 스토리지를 파일 시스템으로 사용합니다


이러한 프레임워크는 일반적으로 마스터 노드와 슬레이브 노드 구조로 운영됩니다. 마스터 노드는 전체 시스템을 제어하고 명령을 전달하며, 슬레이브 노드들은 데이터를 처리합니다. 분산 시스템은 데이터의 **복제본(replication factor)**을 여러 서버에 저장해 두어 일부 서버에 장애가 발생하더라도 작업이 지속될 수 있게 설계되어 있습니다.
이제 DataWareHouse에 대해 자세히 알아보자
-> 회사에 필요한 모든 데이터를 모아놓은 관계형 데이터베이스(SQL로 처리), 기본적으로 클라우드 서비스를 쓴다.
Redshift 초기 설정
access 할 수 있는 account 세팅을 해야된다.
- admin세팅하 admin 사용해서 들어가는 법
- admin 세팅해놓고 aws의 IAM 기능 이용해서 별도의 account이용해서 들어가는 법
-> 그 후 Colab에서 SQLAlchemy라는 모듈 통해서.접속 (Endpoint, Username, Password 이용)


1) Redshift 연결 테스트
%load_ext sql
%sql postgresql://ID:PW@호스트이름:5439/dev #colab과 연결그리고 Redshift에 초기 설정을 해야한다.(스키마, 그룹, 유저, 역할 만들기, 이때 admin 권한이 있어야)
2) 스키마(Schema) 설정

%%sql
CREATE SCHEMA raw_data;
CREATE SCHEMA analytics;
CREATE SCHEMA adhoc;
CREATE SCHEMA pii;
select * from pg_namespace;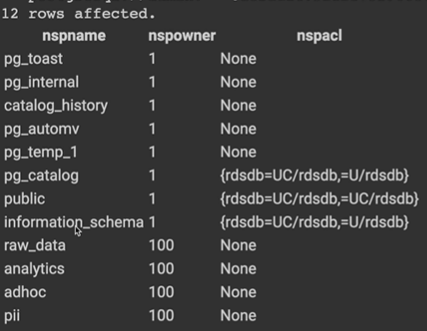
3) User 설정
%%sql
CREATE USER keeyong PASSWORD '*****'; #8글자, 대소문자, 특수문자
select * from pg_user;
4) 그룹/역할 설정
많은 사용자와 테이블이 있을 경우 그룹과 스키마를 이용해 효율적으로 접근 권한을 관리한다.
모든 테이블에 대한 권한을 사용자별로 설정하는 대신 스키마 단위로 접근 권한을 부여한다.
사용자들도 그룹으로 묶어 관리하고 이 그룹에 대해 스키마 접근 권한을 설정한다.
각각의 스키마에 대한 읽기/쓰기 권한을 그룹별로 정의!

그룹의 문제는 계승이 안된다는 점. 많은 그룹을 만들게 되고 관리가 어려워질 수 있다. ->Role개념
권한을 계승해 효율성 높인다. GRANT ROLE 사용
%%sql
CREATE GROUP analytics_users;
CREATE GROUP pii_users;
CREATE GROUP analytics_authors;
ALTER GROUP analytics_authors ADD USER keeyong;
ALTER GROUP analytics_users ADD USER keeyong;
ALTER GROUP pii_users ADD USER keeyong;
CREATE ROLE staff;
CREATE ROLE manager;
CREATE ROLE external;
GRANT ROLE staff TO keeyong; -- keeyong 대신에 다른 역할(Role)을 지정 가능
GRANT ROLE staff TO ROLE manager;
select * from SVV_ROLES;ROLE은 GROUP과 달리 하나 define한 ROLE이 있으면 계승 가능하다.
Redshift COPY 명령(벌크 업데이트)으로 테이블에 레코드 적재하기
1) 테이블 생성
CREATE TABLE 명령으로 raw_data 스키마 아래 세 테이블 만든다. (ETL을 통해 데이터 소스에서 그대로 복사된 형태)
CREATE TABLE raw_data.user_session_channel (
userid integer ,
sessionid varchar(32) primary key,
channel varchar(32)
);
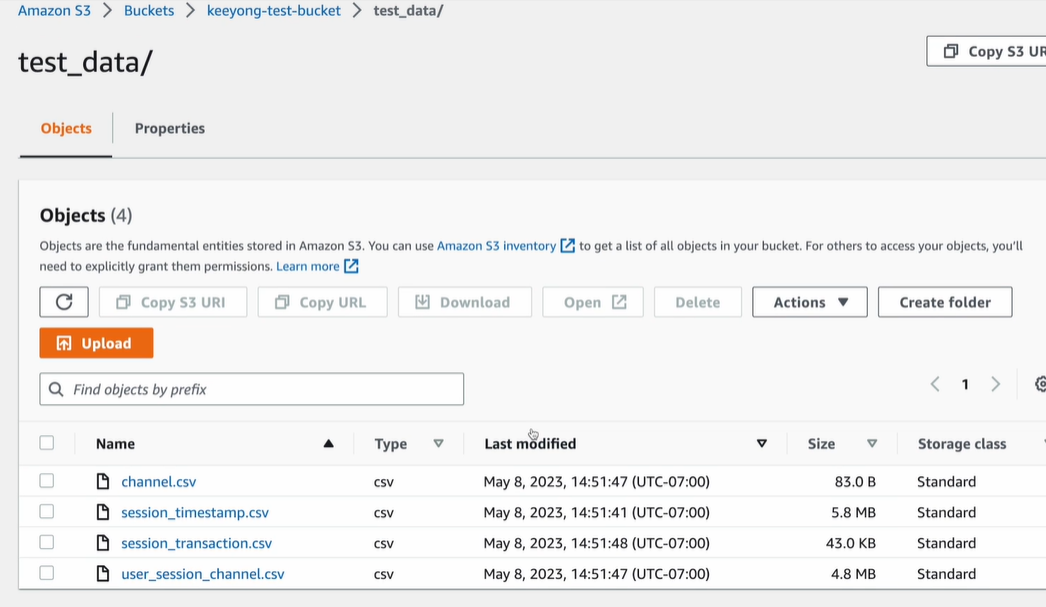
2) S3 버킷 생성과 파일 업로드
테이블에 입력되는 레코드들을 개별적으로 INSERT INTO로 삽입하는 대신,
해당 레코드들을 포함한 CSV 파일을 S3 버킷의 특정 폴더에 업로드
Redshift의 COPY 명령어를 사용하여 S3 버킷에 있는 CSV 파일을 해당 테이블로 일괄 업데이트
S3 객체 경로 : s3://keeyong-test-bucket/test_data/user_session_channel.csv

3) 접근 권한 설정
Redshift가 S3 bucket 에접근 할 수 있는 권한 부여
Redshift Serverless 클러스터가 데이터를 가져올 수 있도록, CSV 파일이 저장된 S3 버킷에 대한 접근 권한을 부여해야 한다. AWS IAM 보안 정책 사용


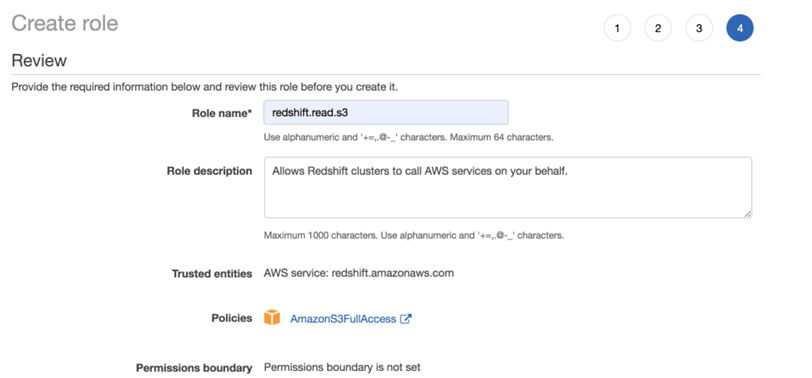
최종 이름으로 redshift.read.s3을 지정하고 최종 생성 ->
readshift.read.s3이라는 역할을 만들고 그 역할에 S3를 접근할 수있는권한을 주었다.
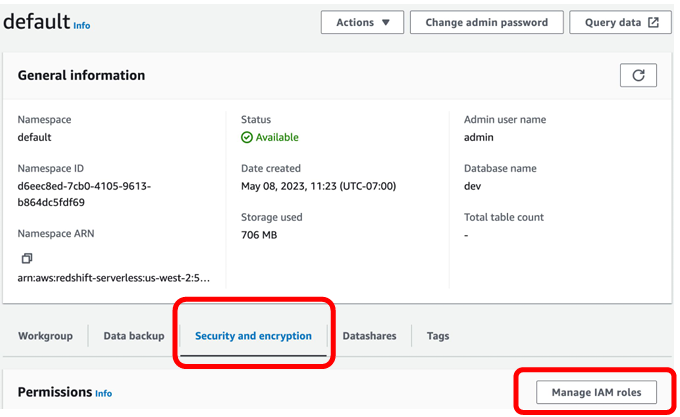
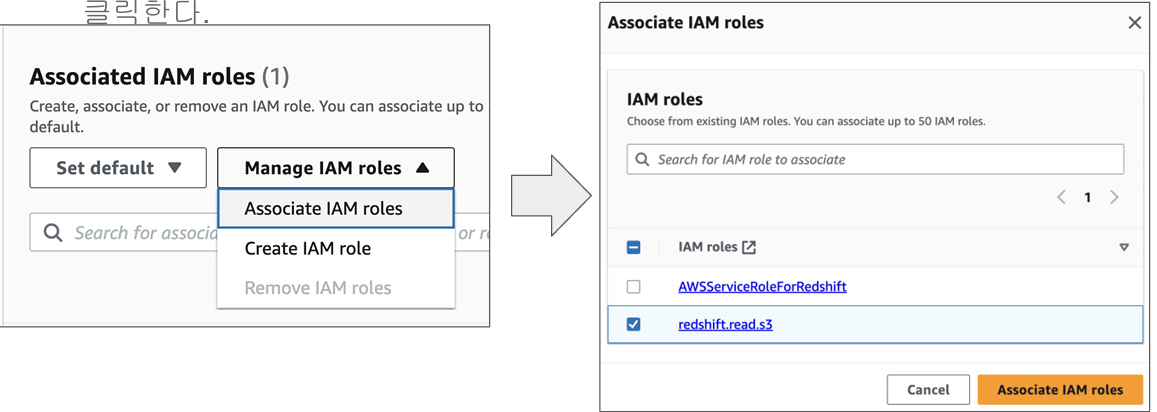

4) COPY 명령을 사용해 CSV 파일들을 테이블로 복사
test_data 밑에 업로드했던 파일들을 3개의 테이블로 각각 벌크 업데이트
COPY raw_data.user_session_channel
FROM 's3://keeyong-test-bucket/test_data/user_session_channel.csv'
credentials 'aws_iam_role=arn:aws:iam:xxxxxxx:role/redshift.read.s3'
delimiter ',' dateformat 'auto' timeformat 'auto' IGNOREHEADER 1 removequotes;- credentials에 앞서 Redshift에 지정한 Role을 사용. 이때 해당 Role의 ARN을
- CSV 파일이기에 delimiter로는 콤마(,)를 지정
- CSV 파일의 첫번째 라인(헤더)을 무시하기 위해 “IGNOREHEADER 1”을 지정
- CSV의 문자열이 ""로 둘러 쌓을 수 있는데 이거를 무시 removequotes
SELECT * FROM stl_load_errors ORDER BY starttime DESCcopy 명령 실행중 에러가 났으면 -> 에러 원일을 볼 수 있다. 이때 starttime의 내림차순으로
ex) csv파일의 특정 column이 문자인데 해당하는 table의 필더가 integer이면, 문자 길이가 충분치 않으면
5) analytics 테스트 테이블 만들기
row data밑에 있는 tablel들은 외부에 있는 data를 읽어다가 COPY 명령을 통해 Bulk Update하는게 특징이다.
analytics는 이미 존재하는 raw_data나 analyacs_data 스키마 밑에 존재하는 테이블들 조인해서 새로 만드는것 (ELT)
DBT라는 툴을 많이 쓰긴 하지만 간단하게 CTAS로 사용할 수 있다.
CREATE TABLE analytics.mau_summary AS
SELECT
TO_CHAR(A.ts, 'YYYY-MM') AS month,
COUNT(DISTINCT B.userid) AS mau
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid
GROUP BY 1
ORDER BY 1 DESC;
Redshift 관련 타 서비스
1) Redshift Spectrum
- Redshift와 같은 지역에 위치한 Amazon S3
- 만약 원본 데이터를 정제를 한다음에 Redshift로 올리고 싶다면?
- Redshift 테이블로 로딩하지 않고도, 즉 데이터 Lake에 저장된 정보를 처리할 수 있는 기능을 Redshift에 구현
- Data Lake에 저장된 데이터와 Redshift 테이블 간의 조인도 가능
- Redshift Spectrum을 이용하면 S3 안에 있는 파일을 External Table 형태로 관리하여 대용량 데이터 분석이 가능
2) Athena
- Redshift Spectrum과 유사한 별도 서비스, Apache Presto를 서비스화한 것
- 비정형 로그 파일 등 다양한 유형의 데이터를 처리하는 데 적합하며, Apache Presto 기반의 SQL 엔진을 활용
Fact 테이블 vs Dimension 테이블
Dimension은 좀더 분석이 가능하게 하는..
둘은 Join key를 갖게 된다.
Redshift에 소규 Dimension이 테이블이 존재
Fact 테이블을 Redshfit로 적재하지 않고 위의 두 테이블을 조인하고 싶다면?
외부 테이블:
데이터 베이스 엔진이 외부에 저장된 데이터를 마치 내부 테이블처럼 사용하는 방법
S3 파일들을 외부테이블들로 처리하면서 Redshift 테이블과 조인 가능
S3 Fact테이터를 external로 전제
external schema를 통해
AWS Glue
데이터 카탈로그:


S3 bucket의 location 기반으로 external table만든다.
3) Redshift ML
- Amazon SageMaker와 연동하여, SageMaker로 생성한 머신러닝 모델을 Redshift 내에서 SQL 함수처럼 사용할 수 있도록
SageMaker는 머신러닝 모델 생성, 테스트, 배포, 모니터링을 지원하는 end-to-end 프레임워크로, AutoPilot 기능을 통해 자동으로 최적의 모델과 하이퍼파라미터를 찾아준다.
Redshift ML을 통해, SQL 쿼리만으로도 모델을 학습시키거나 미리 학습된 모델을 로드하여 Redshift의 테이블 데이터에 대해 예측을 수행
1. Redshift에서 직접 모델을 훈련
2. 이미 학습된 모델을 불러와 함수처럼 사용하여, 특정 테이블의 컬럼을 입력값으로 주고 예측 결과를 SQL 쿼리의 결과로 받아
'Data Engineer > 데브코스' 카테고리의 다른 글
| 데브코스 데이터 엔지니어링 WEEK10 WIL(2) (0) | 2024.11.19 |
|---|---|
| 데브코스 데이터 엔지니어링 WEEK10 WIL(1) (0) | 2024.11.19 |
| 데브코스 데이터 엔지니어링 WEEK8 WIL(2) (0) | 2024.11.19 |
| 데브코스 데이터 엔지니어링 WEEK6 WIL(2) (0) | 2024.11.07 |
| 데브코스 데이터 엔지니어링 WEEK6 WIL(1) (0) | 2024.11.01 |