
예제 테이블 소개
쿠키 vs 세션 vs 토큰 (JWT) -> Auth 구현하기 위해..
쿠키= 그냥 옮기는 매개체
토큰= 서버에게 보여줘야하며, 서버가 기억하는 무지 긴 string (신분증처럼)
JWT= 정보를 갖고있는 토큰. DB없이 검증할 수 있음
서버는 response에 쿠키를 넣어 보낼 수 있다. 내 브라우저 해당 쿠키를 저장하고 해당 웹사이터 갈때마다 보낸다.
쿠키는 도메인에 따라 제한되고 서버가 정한 기간이 지나면 사라진다.
쿠키에는 인증 뿐 아니라 언어설정 바꾼거 기억할 수 도 있음
HTTP 프로토콜은 stateless하다. 서버로 가는 모든 요청이 이전 request와 독립적으로 다뤄진다.
요청이 끝나면 서버는 누군지 잊어버리기 때문에 요청할 때마다 우리가 누군지 알려줘야한다.
이를 하기 위한 방법이 세션이다.
만약 아이디 비번 맞게 전달하면 서버는 세션 DB에 유저를 생성하고 unique한 id를 만든다.
이 DB는 redis사용(매우 빠르고 저렴)
이 id는 쿠키를 통해 클라이언트의 브라우저로 돌아가고 저장된다.
따라서 같은 웹사이트의 다른 페이지로 이동하면 브라우저는 세션 ID를 갖고있는 쿠키를 서버한테 보낸다. (쿠키는 자동으로 보내짐)
서버는 들어오는 쿠키를 보고 세션 ID를 확인한다. 그리고 세션 DB를 확인해 해당 ID의 유저명을 찾는다.
즉 모든 정보는 서버의 DB에 저장되어있고 유저가 갖고있는 것은 세션 ID 뿐이다.
쿠키는 그저 세션 ID를 전달하기 위한 매개채!
모바일 애플리케이션은 쿠키를 사용할 수 없다 브라우저에만 있으니까
이경우에는 토큰을 서버에 보낸다.
그냥 이상하게 생긴 String. 서버는 세션 DB에서 해당 토큰과 일치하는 유저를 찾는다.
기억할거는 서버는 로그인한 유저들의 모든 세션 ID를 DB에 저장해야된다. 로그인할 때마다, 유저가 늘어날때마다 database더 필요
이때 JWT등장, JWT는 토큰 형식이다. JWT는 세션 DB를 갖출 필요 없다. 서버가 유저 인증한다고 많은 일 하지 않아도 됨
대신 서버는 유저의 ID를 가져다가 사인 알고리즘을 하고 사인된 정보를 string 형태로 보낸다. DB를 건드리는대신 사인만하고 끝
이제 다시 서버에 요청 보내려면 사인된 토큰을 보내고 토큰을 받으면 유효한지 체크하고 유효하다면 우리를 유저로 인증한다.
세션에서는 그냥 세션 ID만 주면된다. 세션에 대한 모든 정보는 세션 Db에 저장되어있고 페이지 요청하면 서버는 세션 ID를 DB에서 찾으면 된다.
토큰은 해당 토큰이 유효한지만 검사. DB에 저장할 필요 없이
세션을 이용하면 서버는 로그인 된 유저의 모든 정보를 저장하기 때문에 해당 정보를 이용해 새로운 기능들 추가할 수 있다. 특정 유저를 쫓아내거나 로그인된 모든 device들..
마케팅에 관련된 테이블: 사용자 ID, 세션 ID
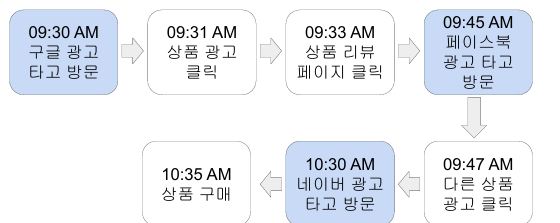
세션은 사용자가 웹서비스를 방문할 때 논리적인 단위로 나누는 것.
논리적 단위?
1) timebound를 두어서 사이트를 방문하는 순간 session을 하나 만들고
30분동안 아무것도 안하면 그 때 세션이 종료된다. 그 세션에 id 부여
2) 외부링크를 타고 오는 순간. 이미 이 사이트에 방문했고 30분이 안지난 상태에서도 외부에서 광고와 같은 링크를 클릭해서 들어오면 세션을 새로 만든다. 어떻게 사이트를 방문했는지 트랙킹하고 싶어서.이것은 마케팅 기여도 분석하는데 도움을 준다.
즉 하나의 사용자는 여러 세션을 가질 수 있고 세션을 만들 때마다 경유지를 채널이란 이름이로 기록해둔다.
브라우저의 주소창에서 타이핑하거나 북마크로 찾아간경우에는 접점이라는 게 없고 direct visit이라고 한다.
유튜브에서 광고를 보고 클릭했다면 접점이 생기고 접점을 channel이라고 부른다.
세션들을 보고 세션을 가장 많이 만들어낸 채널 접점이 뭔지 파악한다.
세션을 가장 많이 만든 채널을 보고 이러한 곳에 광고하는것이 이득이라고 판단 (디지털 마케팅에 아주 중요)

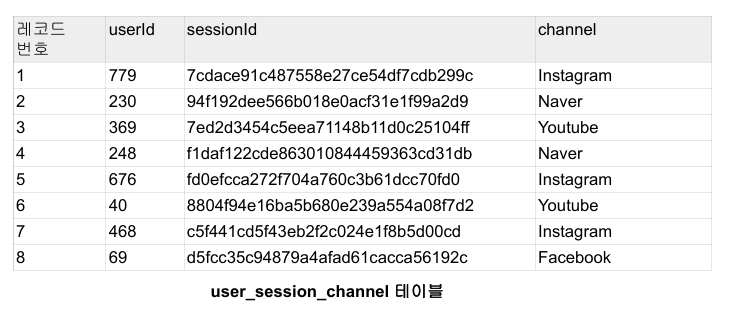
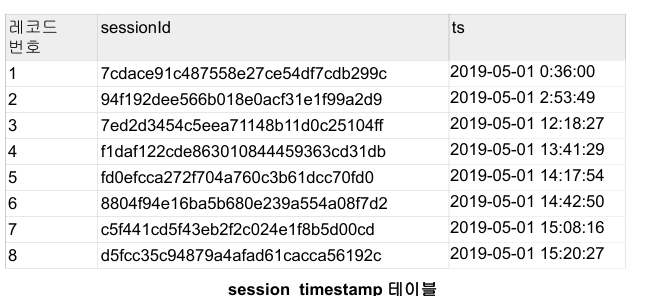
이정보를 기반으로 다양한 데이터 분석과 지표 설정이 가능해진다. (마케팅 관련, 사용자 트래픽)
DAU,WAU, MAU Active User들 파악
추가로 이 세션을 통해서 실제로 구매가 일어 났는지
데이터 품질 체크!
1) 중복된 레코드 체크

2) 최근 데이터의 존재여부 체크

3) Primary key uniqueness 지켜졌는지 체크

4) 값이 비어있는 컬럼들 있는지

5) 위의 체크는 코딩의 unit test형태로 만들어 매번 쉽게 체크
SQL 상세
주피터 노트북을 sql editor처럼
파이썬 코딩과 섞어서
%load_ext sql
%sql postgresql://sjisno_1:Sjisno_1!1@learnde.cduaw970ssvt.ap-northeast-2.redshift.amazonaws.com:5439/dev또한 sql들과 판다스를 쉽게 연동할 수 있다.
result = %sql SELECT * FROM raw_data.user_session_channel
df = result.DataFrame()result에 DataFrame() 부르면 return되는 값이 판다스 dataFrame이다.
그다음 부터는 그냥 pandas쓰는거랑 같다.


1) SELECT
SELECT하면 결과가 Table로 return






2) Group BY + Aggregate 함수
가장 많이 사용된 채널

월별 유니크한 사용자수(MAU) - 한사용자는 한번만 카운트 되어야함


DISTINCT 없이 COUNT하면 모든 userid에 대해서 1을 계속 추가한다
timestamp->month 다양한 방법

월별 채널별 유니크한 사용자수

3) CTAS CTE
CTAS
SELECT가지고 테이블 생성
JOIN된 테이블을 만들고 싶을 때 유용
CTE

임시 테이블 생성. ds는 테이블 이름
위로 빼면 밑에서 재사용할 수 있기 때문에 더 좋다.
4) JOIN
join할 때는 먼저 중복 레코드가 없고 Primary Key의 uniqueness가 보장됨을 체크해야한다.
또 Join하는 테이블간의 관계를 명확하게 정의하자
5) 최종 보스 문제

- JOIN시 JOIN 전략부터! session_transaction의 경우 모든 sessionid가 존재하지 않음 -> LEFT JOIN
- TypeCasting 분자나 분모 아무거나 실수형으로

최종 답

6) Boolean, NULL 처리
- Boolean
다음 2개는 동일한 표현
flag = True
flag is True
이 2개는 다름
flag is True
flag is not Flase
- NULL
NULL 비교는 항상 IS 혹은 IS NOT으로 수행
NULL 비교를 = 혹은 != <>으로 수행하면 에러가 아닌 잘못된 결과가 나와 힘듬




7) Transaction
Atomic하게 실행되어야 하는 SQL들을 묶어서 하나의 작업처럼 처리하는 방법
Atomic?
여러개의 SQL이 동시에 성공 or 실패해야지 데이터의 정합성에 문제 없는 경우
계좌이체의 경우 인출은 성공했는데 입금이 실패한다면? -> Atomic하다.
이러한 과정들을 트랜잭션으로 묶어줘야한다.
Atomic하게 실행되어야하는 SQL들은 쓰기작업(DB의 상태를 바꾸는)것에만 의미가 있다.
예를 들어 조회하는것(operation이 다 SELECT)이라면 굳이 Atomic하게 만들 필요 없다.
BEGIN과 END 혹은 BEGIN COMMIT 사이에 해당 SQL들을 사용하고 그 중간의 SQL이 하나라도 실패하면 원래 상태로 돌아간다.
이를 ROLL BACK이라고 한다.
SQL의 transaction은 commit mode에 따라 달라짐!
auto commit이 True이냐 False이냐에 따라서 구현하는 방법이 달라진다.
autocommit = True
create, update같은 작업을 하면 바로 데이터베이스에 반영된다. (이를 Commit이라함)
만일 특정 작업을 트랜잭션으로 묶고 싶다면 BEGIN과 END(COMMIT)/ROLLBACK으로 처리
autocommit = False
모든 데코드 수정/삭제/추가 작업이 COMMIT 호출될 때 까지 커밋 되지 않음
즉 BEGIN END 모드가 모든 쓰기 operation에 대해 적용
나한테는 적용된것이 보이지만 남한테는 보이지 않는다.
DELETE FROM vs TRUNCATE
DELETE FROM 은 레코드를 삭제하는것 (테이블은 남아있음)
TRUNCATE은 테이블에서 모든 레코드를 삭제하는것(DELETE FROM보다 빠름)
DELETE FROM은 transaction안에서 사용할 수 있고 ROLLBACK이 가능하다
반면 TRUNCATE은 transaction안에 쓰더라도 롤백이 안된다.
그래서 TRUNCATE은 내가 정말 Rollback할 일 이 없는데 Table을 삭제하고 싶은 경우 사

Redshift를 파이썬을 이용해 autocommit을 바꿔가면서 해보자.
psycopg2는 Python에서 PostgreSQL 데이터베이스와 연결하고 쿼리 실행 할 수 있는 라이브러리



더 파이써닉 하게

'Data Engineer > 데브코스' 카테고리의 다른 글
| 데브코스 데이터 엔지니어링 WEEK10 WIL(2) (0) | 2024.11.19 |
|---|---|
| 데브코스 데이터 엔지니어링 WEEK10 WIL(1) (0) | 2024.11.19 |
| 데브코스 데이터 엔지니어링 WEEK8 WIL(2) (0) | 2024.11.19 |
| 데브코스 데이터 엔지니어링 WEEK8 WIL(1) (0) | 2024.11.07 |
| 데브코스 데이터 엔지니어링 WEEK6 WIL(1) (0) | 2024.11.01 |